17 Jun 2022
In this week, CoreXT is officially deprecated from the NSM repository – more accurately other than using it in legacy
dialtone support, CoreXT is behind us in the daily development. The days of dealing with all the non-standard build
system are over. With that, I can describe some historical technical details for learning purpose.
As previously described, the CoreXT is to ensure the product build can be reproducible, consistent, and reliable. In the
latest version, it supports all kinds of projects, including regular C# libraries and executables, C/C++ native code,
Service Fabric micro-services, Windows Workflow, NuGet package generation, VHD generation, code signing (both
Authenticode and strong name signing), build compositions, etc. In this note, I specifically discuss a few common
questions regarding the package management in CoreXT.
Firstly, assuming you know the basics of C# project build, for instance create a new project in Visual Studio and save
it, you may find the following files:
*.cs: C# source code.*.csproj: an XML file to describe the project, such as name, type, source code, references etc. This is consumed by
MSBuild program. We also call it project file.*.sln: solution file is mainly for Visual Studio IDE as a collection of project files. MSBuild can parse it during
the build, but in CoreXT it is not part of the build process.
When we run “Build Project” in Visual Studio IDE or run “msbuild” in the developer command prompt, MSBuild program will
read project files, such as csproj, and follow its instruction to compile the source code into OBJ files (often save
them in “obj” directory) and then link them to DLL or EXE files (often save them in “bin” directory).
Any non-trivial projects usually have some dependencies, or the references during the compile time (and load them
during the runtime). Some dependencies are part of the .NET framework, which we don’t need to worry about. The question
is how to manage the references (DLL files and other collaterals) with the projects. This is why we need package
management.
The most common package management in CoreXT, in fact the only one that I use, is NuGet. In public environment, many
NuGet packages (a.k.a. nupkg) are stored in nuget.org, Visual Studio can manage the download, install, upgrade work.
When we add a nupkg in a legacy project (we will come to the format later), we may notice the following:
- NuGet.config file is added optionally to describe where the NuGet server is, and where to save the packages locally.
- Packages.config file is added to list the package names and their versions.
- In csproj file, the reference may use a relative path to locate the DLL in the installed packages.
This works for a single, personal, project. Where the number of the project grows, or multiple developers share a source
repository this does not work because many packages.config file will be messy, and we cannot expect everyone store nupkg
in the same path. CoreXT solves the problem in this way:
-
Store all instances of NuGet.Config and Packages.config files in a central location, which is .corext/corext.config.
This file lists the nupkg server locations, and list of nupkg names and versions used in the entire source repository.
-
When the dev environment is initialized by running init.cmd, download all nupkgs to the directory specified by
environment variable NugetMachineInstallRoot (e.g. D:\CxCache), record their locations in PROPS file which is injected
into every CSPROJ. If there is a nupkg named “Microsoft.Azure.Network” version 1.2.3, the install location may be
D:\CxCache\Microsoft.Foo.Bah.1.2.3, and a variable PkgMicrosoft_Azure_Network will be defined in PROPS file and
point to the location on the local file system.
-
Argo program will scan all PROJ files and replace absolute/relative paths in “Reference” element with the variables
defined in the PROPS file. For instance, if we add a DLL refernece with path
D:\CxCache\Microsoft.Azure.Network.1.2.3\lib\net45\Abc.dll, it will replace with the value
$(PkgMicrosoft_Azure_Network)\lib\net45\Abc.dll.
-
Above approach solves the most problems for regular DLL references. For running commands outsides of MSBuild,
corext.config has a section to specify which nupkg paths will be defined in environment variables.
Unlike packages.config, corext.config is able to handle multiple versions. For instance, if some projects need to use
version 1.2.3 some use 2.3.4 of package Microsoft.Network.Abc, then we will write the following:
<package id="Microsoft.Network.Abc" version="1.2.3" />
<package id="Microsoft.Network.Abc" version="2.3.4" />
In PROPS file the following variables will be created:
PkgMicrosoft_Network_Abc pointing to the highest version, i.e. 2.3.4.PkgMicrosoft_Network_Abc_2 pointing to the highest version 2, i.e. 2.3.4.PkgMicrosoft_Network_Abc_2_3, similarly to 2.3.4.PkgMicrosoft_Network_Abc_2_3_4 to 2.3.4.PkgMicrosoft_Network_Abc_1 to 1.2.3.PkgMicrosoft_Network_Abc_1_2 to 1.2.3.PkgMicrosoft_Network_Abc_1_2_3 to 1.2.3.
If a project wants to references the highest version always, it will use PkgMicrosoft_Network_Abc. If the project
wants to lock on version 1 instead, it will use PkgMicrosoft_Network_Abc_1 instead.
With the above basic principle in mind, now let us address a few questions.
Q: What’s the need for packages.config in CoreXT?
Packages.config files should be merged into corext.config, they should not exist. But if they do, CoreXT will install
the packages listed there, just like another copy of corext.config.
Q: What about app.config?
This is unrelated to package management. In the build process, this file will be copied to the output path and renamed
to the actual assembly name. For instance, if “AssemblyName” in CSPROJ is Microsoft.Azure.Network.MyExe and the
project type is executable, app.config will become “Microsoft.Azure.Network.MyExe.exe.config”.
Q: What is the difference between CSPROJ and PROJ?
Both are MSBuild project files with the same schema. People usually rely on the file extension to tell what the
project is for, for instance CSPROJ for C# projects, VBPROJ for Visual Basic projects, SFPROJ for Service Fabric
projects, NUPROJ for NuGet projects, etc. Sometimes people run out of ideas, or manually write project files, then
they just call it PROJ.
Q: Is it a good idea to share same corext.config among multiple projects?
Of course. In fact, all projects in the source repository share a single corext.config. Keep in mind the intention of
corext.config is to aggregate multiple packages.config.
Q: Then how to handle the case where my project wants to use a different version?
See above explanation.
Q: This seems like a mess, any simpler way to not deal with corext.config?
Many source repositories have started to migrate from CoreXT to retail MSBuild with package reference. If you can find
“Packages.props” file in the top directory and see “MSBuild.Bridge.CoreXT” in corext.config, it probably means both
legacy and modern SDK-style projects are supported. In the latter, no CoreXT is involved. You may read Introducing
Central Package Management for some
ideas. If you need more practical knowledge, ping me offline.
If anyone has more questions, I will compile them in this note.
16 Jun 2022
Sometimes we have to debug the process crashing issue during the startup. The problem to handle this in Windows Debugger
(a.k.a. windbg) is that the process dies very quickly, by the time you want to attach the debugger the target process is
already gone. A well known solution is Image File Execution Options. We can either run gflags or set a registry key
so the debugger is automatically started when the process is started. For more information, visit Image File Execution
Options. In
short, we can add a key at the following location:
HKLM\Software\Microsoft\Windows NT\CurrentVersion\Image File Execution Options
the name of the key is the EXE file name, such as “notepad.exe”, then add a string value with name “Debugger” and value
“C:\Debuggers\windbg.exe”, where the value points to the full path of the debugger executable.
Note that the debugger process will be running in the same login session as the process being debugged. If the process
is launched by a Windows system service (or Service Fabric micro-services) in the session 0, the deugger will be too. In
other words, we cannot see the debugger so cannot do anything. The solution for this is to start a debugger server in
session 0 and connect to it from the current login session. For instance, if we want to attach to debugger when
notepad.exe is started, the registry value will be:
C:\Debuggers\ntsd.exe -server npipe:pipe=dbg%d -noio -g -G
This means whenever Windows wishes to launch “notepad.exe” it will run above command and add “notepad.exe” at the end,
effectively start a debug session. The parameters are:
- Start a debugger server with a named pipe with the specified name, and the NTSD process ID is the suffix so it is
possible to debug multiple instances.
- No input or output.
- Ignore the initial breakpoint when the process is started.
- Ignore the final breakpoint at process termination.
Now find the NTSD process ID using the Task Manager or the command line:
d:\rd\Networking\NSM\src\nsm\NetworkManager\Logging\Logging>tasklist | findstr /i ntsd
ntsd.exe 18816 RDP-Tcp#0 2 27,496 K
Then we can connect to the debug server:
C:\Debuggers\windbg -remote npipe:pipe=dbg18816,server=localhost
Note that the pipe name has the NTSD PID.
Finally, do not forget to set the symbol server path. Within the Microsoft corpnet the following environment variable is
recommended (assuming the cache is at D:\sym):
_NT_SYMBOL_PATH=srv*d:\sym*http://symweb
25 Dec 2020
The release of .NET 5.0 is an exciting news for us. No more argument whether to migrate to .NET core or upgrade to newer
version of .NET framework, .NET 5 or 6 (LTS version) will be the north star for control plane services with better
performance and faster speed of innovations. Additionally it is relieving to know multiple platforms (not just different
editions of Windows) can be unified with one set of source code.
Today I found a little cute Raspberry Pi 3B lying
unused. It was a toy for my son but he got a real computer already. I wondered whether it was able to run .NET 5 apps,
so I decided to give a try. The process turns out to be quite straightforward, although I don’t think it’s useful to do
so. Anyway here is what I’ve done.
Upgrade Raspberry Pi OS
Although no endpoint is opened, it is still a good practice to keep the OS up to date:
sudo apt update
sudo apt upgrade
sudo apt full-upgrade
sudo autoremove
Setup Docker
My work doesn’t actually use Docker, but I was curious whether it runs in such a resource-constrained environment.
Firstly, run the script from the official website:
curl -sSL https://get.docker.com | sh
In order to not prefix almost all commands with sudo, I added the default user account to the docker user group:
sudo usermod -aG docker pi
Then ran a smoke testing:
docker version
docker info
docker hello-world
It was encouraging to see everything just works.
Install .NET SDK 5.0.1
Initially I thought package management might take care of this. But I had to do it manually like the following:
wget https://download.visualstudio.microsoft.com/download/pr/567a64a8-810b-4c3f-85e3-bc9f9e06311b/02664afe4f3992a4d558ed066d906745/dotnet-sdk-5.0.101-linux-arm.tar.gz
sudo mkdir /var/dotnet
sudo tar zxvf dotnet-sdk-5.0.101-linux-arm.tar.gz -C /var/dotnet
Then I created a sample console app to confirm it indeed worked. Lastly, I changed $HOME/.bashrc for required change
of environment variables.
Visual Studio Code
VI is preinstalled on Raspberry Pi, just like every other Linux distributions. However, VS Code is so popular that I
must give a try. After download the Debian package from VS Code download site, I installed it with the following:
sudo apt install ./code_1.52.1-1608136275_armhf.deb
Now the “development” environment is ready. Understandably nothing is as responsive as my desktop, but it isn’t slow to
the point of unbearable. In fact, writing a simple code was just fine.
Since .NET already provides a sample docker image, why not give a try:
pi@raspberrypi:~ $ docker run --rm mcr.microsoft.com/dotnet/samples
Unable to find image 'mcr.microsoft.com/dotnet/samples:latest' locally
latest: Pulling from dotnet/samples
c06905228d4f: Pull complete
6938b34386db: Pull complete
46700bb56218: Pull complete
7cb1c911c6f7: Pull complete
a42bcb20c9b3: Pull complete
08b374690670: Pull complete
Digest: sha256:9e90c17b3bdccd6a089b92d36dd4164a201b64a5bf2ba8f58c45faa68bc538d6
Status: Downloaded newer image for mcr.microsoft.com/dotnet/samples:latest
Hello from .NET!
__________________
\
\
....
....'
....
..........
.............'..'..
................'..'.....
.......'..........'..'..'....
........'..........'..'..'.....
.'....'..'..........'..'.......'.
.'..................'... ......
. ......'......... .....
. ......
.. . .. ......
.... . .......
...... ....... ............
................ ......................
........................'................
......................'..'...... .......
.........................'..'..... .......
........ ..'.............'..'.... ..........
..'..'... ...............'....... ..........
...'...... ...... .......... ...... .......
........... ....... ........ ......
....... '...'.'. '.'.'.' ....
....... .....'.. ..'.....
.. .......... ..'........
............ ..............
............. '..............
...........'.. .'.'............
............... .'.'.............
.............'.. ..'..'...........
............... .'..............
......... ..............
.....
Environment:
.NET 5.0.1-servicing.20575.16
Linux 4.19.66-v7+ #1253 SMP Thu Aug 15 11:49:46 BST 2019
The following is a screenshot of VS Code:
Create a Docker Image
It was not tricky to create a Docker image using the official .NET 5.0 image. The following command shows the pulled
image:
docker pull mcr.microsoft.com/dotnet/runtime:5.0
After copying the published directory to the image, it ran smoothly. However, I found the image was quite large in size,
the above was 153 MB. After some trial and error, I found a way to make it smaller.
Firstly, change the csproj file to enable Self-Contained-Deployment with trimming, and also turn off globalization since
I almost never need to deal with it in the control plane:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net5.0</TargetFramework>
<InvariantGlobalization>true</InvariantGlobalization>
<PublishTrimmed>true</PublishTrimmed>
<TrimMode>link</TrimMode>
<TrimmerRemoveSymbols>true</TrimmerRemoveSymbols>
</PropertyGroup>
</Project>
Then a SCD package was published to out directory:
dotnet publish -c release -r ubuntu.18.04-arm --self-contained -o out
Note that it is specifically targeted to Ubuntu 18.04 LTS. The package size seems to be reasonable given the runtime is
included:
pi@raspberrypi:~/tmp $ du -h out
16M out
A docker file is written to build image on top of Ubuntu 18.04 minimal image:
FROM ubuntu:18.04
RUN mkdir /app
WORKDIR /app
COPY out /app
ENTRYPOINT ["./hello"]
Build the image:
docker build --pull -t dotnetapp.ubuntu -f Dockerfile.ubuntu .
Give a try to the image and compare with the execution outside of container:
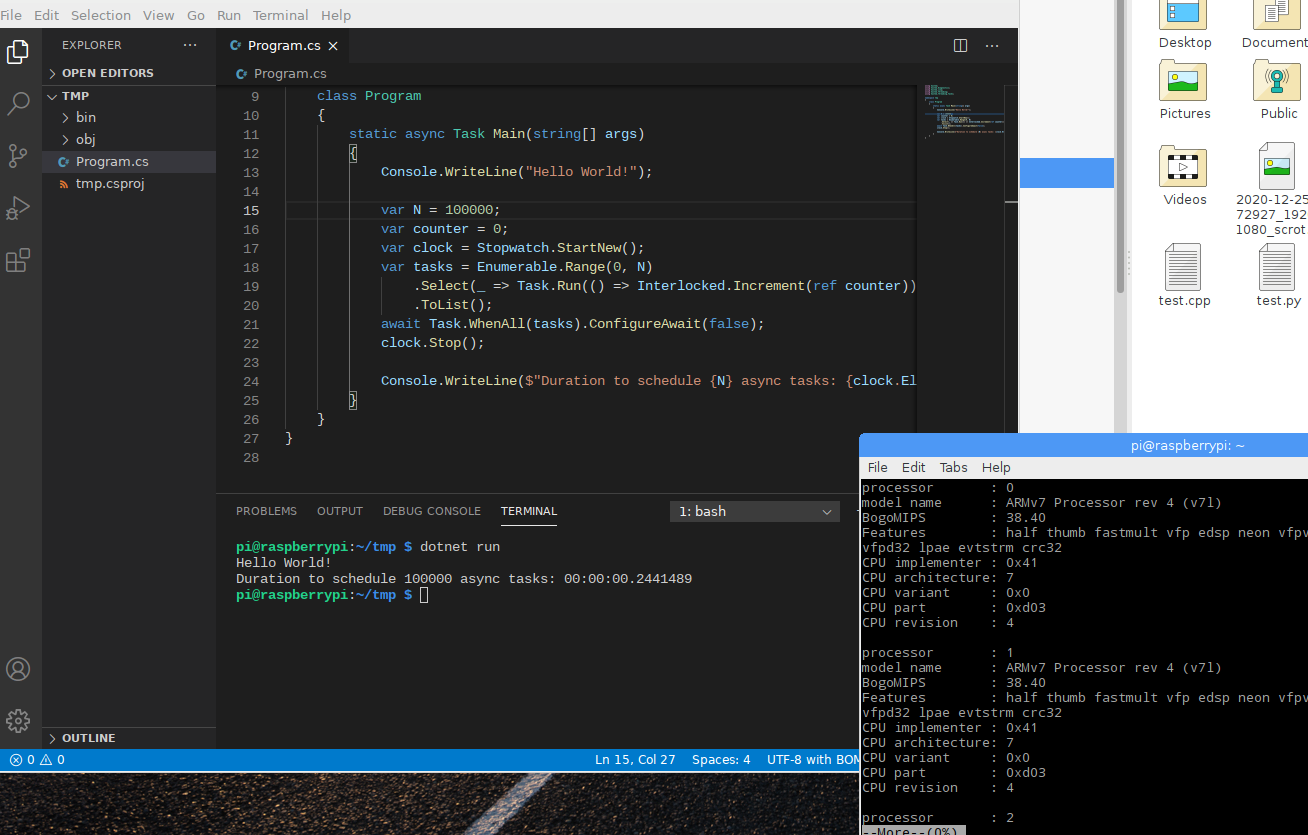
pi@raspberrypi:~/tmp $ docker run --rm dotnetapp.ubuntu
Hello World!
Duration to schedule 100000 async tasks: 00:00:00.2684313
pi@raspberrypi:~/tmp $ out/tmp
Hello World!
Duration to schedule 100000 async tasks: 00:00:00.2351646
Besides Ubuntu, 18.04 I tried other images as well. Here is what I found:
- Debian 10 Slim image works similarly as Ubuntu 18.04, the size is about 3 MB larger.
- Default Alpine image doesn’t have glibc, which is required by the bootstrapper. The packaging works but the image
doesn’t run even the runtime identifier is set to Alpine specifically.
- Google image
gcr.io/distroless/dotnet works, but the base image is 134 MB already since it ships the entire runtime.
- The base image
gcr.io/distroless/base has glibc, the base image is only 13 MB (Ubuntu is 45.8 MB). However, I
didn’t figure out how to fix image build problem. It seems missing /bin/sh is problematic.
- The base image of busybox with glibc is only 2.68 MB. Seems promising, but it doesn’t have required libs
arm-linux-gnueabihf (both at /lib and /usr/lib). I guess it can be resolved by copying some files but in real work
this would be unmaintainable.
By the way, other than new apps many things haven’t changed much on Linux, for instance font
rendering is still miserable and requires heavy modification. Practically WSL
seems to be more productive from development perspective.
20 Dec 2020
In distributed computing, we rely on traces and metrics to understand the runtime behavior of programs. However, in some
cases we still need assistance from debuggers for live-site issues. For instance, if the service crashes all of sudden
and no trace offers any clue, we need to load crashdump into debugger. Or some exception is raised but traces are
insufficient to understand the nature of the problem, we may need to capture a full state of the process.
In old days, at least starting in Windows 3.1, there was a Dr. Watson
to collect the error information following a process crash, mainly the crash dump file. Every time I saw it, something
bad happened. Nowadays it has been under the new name of Windows Error
Reporting, or WER. Inside the platform,
there is still a “watson” service to collect all the crashdumps created by the platform code, process it, assign to the
right owner, and send alerts as configured. Some times during live-site investigation, we can also request a dump file
collection using “Node Diagnostiics”, then the file will be taken over by Watson (assuming your hand isn’t fast enough
to move the file somewhere else).
Like it or not, to look at the dump file you have to use
windbg. You can choose cdb
or windbgx but they are not really different. If you are too busy to learn how windbg
works, particularly
managed code debugging using
SOS, then you may use this
quick guide to save some time.
Debugger extensions
Download sosex from Steve’s TechSpot and save the DLL in the extension directory.
Download mex from Microsoft download and save the
DLL in the extension directory.
To find the extension directory, find the directory at where windbg.exe is located using Task Manager, then go to
winext directory.
Basic commands
Exit windbg: enter qd or simply Alt-F4.
Display process environment block
Wou will see where the execution image is, all the environment variables which contains the machine name, processor ID,
count, etc.
CPU usage
To check which threads have consumed how much CPU time:
To check CPU utilization, thread pool worker thread and completion port thread usage:
List of threads: check if how many threads there are, any threads are terminated or hitting some exception, etc.
If you click the blue underlined link you can switch to that thread, then use the following to see the native stack
trace:
or see the managed stack trace
To check the object on the stack run the following:
To check the local variables of a specific frame (use the frame number in “k” output):
Object count: to get the statistics of objects in the managed heap.
If you want to get the live objects (the objects that cannot be garbage collected), add -live parameter. If you want
to get the dead object, add -dead parameter.
Find object by type name: firstly find the list of types with statistics by the type name (either full name of
partial):
!dumpheap -stat -type MyClassName
Then click the method table link, which is essentially:
!dumpheap /d -mt [MethodTableAddress]
You can click the address link to dump the object, or
A better way to browse the object properties is to use sosex:
!sosex.mdt [ObjectAddress]
To know why it’s live, or the GC root:
or use sosex
!sosex.mroot [ObjectAddress]
Symbols
Check the current symbol path, you use use menu or
Add a directory where PDB files (symbols) are located, use menu or
.sympath+ \\mynetworkshare\directory\symbols
Find all the class names and properties with a particular string (use your own wildcard string):
!sosex.mx *NetworkManager
List of all modules loaded:
To get the details about a module, click the link in above output or:
lmDvm MyNameSpace_MyModule
Here you can see the file version, product version string, timestamp, etc. For the files from many repos, you can see
the branch name and commit hash. If you are interested in the module info:
!lmi MyNameSpace_MyModule
To show disassembled IL code, firstly switch to a managed frame, then run mu:
!sosex.mframe 70
!sosex.mu
Advanced
Find unique stack traces: this will go through the stack trace of all threads, group them by identical ones, and
show you which stack has shown up how many times:
Often times you can see lock contentions or slow transaction isuse, etc.
Find all exceptions:
Dump all async task objects:
If you have to debug memory related issue, refer to my previous post.
Further reading
Many debugging topics are not covered, for instance finalization, deadlock, locking, etc. If quick guidance is
insufficient, please spend some time starting from Getting Started With Windows
Debugging or
the book Advanced .NET
Debugging.
19 Dec 2020
In cloud computing, a prevailing design pattern is multiple loosely coupled
microservice working in synergy to build the app, and
RPC is used for inter-service communication. The platform itself
is no exception. If you are interested in how we (mainly the services I worked on) use RPC, keep reading.
External and Internal Interface
Some services are exposed to public internet using published API contract, for instance xRP (resource providers).
Usually the API is defined in a consistent and platform-neutral manner, such as REST with JSON payload. Typically the
underlying framework is some form of ASP.NET. In this note customer facing services are not discussed.
For internal services that are not exposed to external customers, we have a lot of freedom to choose what works the best
for the context from the technical perspective. In theory, one can choose any protocol one may feel appropriate. In
practice, because of conformity and familiarity, most of time the design choice is converged to a few options as
discussed in the note.
Authentication
Before starting further discussion, it is helpful to understand a little bit on service to service authentication, which
always scopes down the number of options facing us. In the past, when we choose the communication protocol we look at if
two services are within the same trust boundary or not. If a unsecure
protocol is used for talking to a service outside of your trust boundary, the design will be shot down before anyone has
a chance to use it in either internal review or compliance review with the security team. The trust boundary of services
can be the fabric tenant boundary at deployment unit level, or within the same Service Fabric cluster. The most common
case is within the trust boundary use unencrypted protocol, outside of trust boundary secure protocol must be used.
The most common authentication is based on RBAC. No one has
persisted privileged access to the service, engineers request JIT access before conducting privileged operations, source
service has to request security token in order to talk to destination service. Foundational services typically use
claims-based identity associated with the
X.509 certificate provisioned with the service. For people who are familiar with
HTTP authentication, the authentication is
orthogonal and usually separated from the data contract for the service communication. This means we need some way to
carry the OOB payload for the authentication headers.
Some services choose to not use RBAC due to various reasons, for instance it must be able to survive when all other
services are down, or resolve the circular dependency in the buildout stage. In this case, certificate-based
authentication is used with stringent validation. Because certficate exchange occurs at the transport level, it is
simpler to understand and more flexible to implement, although I personally don’t like it because of the security.
WCF
WCF, or Windows Communication Foundation is a framework for
implementing Service-Oriented Architecture on .NET
platform. Based on SOAP WCF supports interoperability with standard web services
built on non-Windows platform as well. It is extremely flexible, powerful, and customizable. And the adoption barrier is
low for developers working on .NET platform. Naturally, it has been the default option for internal RPC. As of today,
many services are still using it.
The common pattern is that unencrypted communication uses NetTcp
binding, if cert-based authentication is
required HTTP binding is used, if RBAC
is needed federation HTTP
binding is used.
For years WCF has been supporting the cloud well without being criticized. However, it is not without downside,
particularly people feel it offers too much flexibility and complexity that we often use it incorrectly. The fact is
most people follow the existing code patterns and do not learn it in a deep level prior to using the technology. After
enough mistakes are made, the blame is moving from people to the technology itself, we need to make things easy to use
otherwise it won’t be sustainable. The following are common problems at this point.
Timeout and retries
When using WCF, it is important to configure timeout
values
correctly. Unfortunately, not everyone know it, and the price is live-site incident. Considering the following scenario:
- Client sends a request to serve. Now it waits for response back. Receive timeout is one minute.
- The operation is time consuming. It is completed at the server side at 1.5 minutes.
- No response is received at the client side after 1 minute, so the client side considers the request has failed.
- Now the state at client and server sides is inconsistent.
The issue must be considered in the implementation. Often times, the solution is to handle the failures at the transport
layer with retries. Different kinds of back-off logic and give-up threshold may be used, but usually retry logic is
required to deal with intermittent failures, for instance catch the exception, if communication exception then tear down
the channel and establish a new one. In the testing or simulation environment this works well. In real world, when a
customer sends a request to the front-end, several hops is needed to reach the backend which is responsible for the
processing, and each hop has its own retry logic. Sometimes uniform backoff is used at certain hop to ensure the
responsiveness as a local optimization. When unexpected downtime occurs, cascading effect is caused, the failure is
propagated to the upper layer, multi-layer retry is triggered, then we see avalanche of requests. Now a small
availability issue becomes a performance problem and it lasts much longer than necessary.
The problem is well known and has been dealt with. However, it never goes away completely.
Message size
For every WCF binding we must configure the message size and various parameters correctly. The default values don’t work
in all cases. For transferring large data,
streaming can be used,
however in reality often times only buffered mode is an option. As the workload increases continuously, the quota is
exceeded occasionally. This has caused live-site incidents several times. Some libraries (e.g. WCF utility in SF) simply
increase those parameters to the maximum, and that caused different set of problems.
Load balancer friendly
In many cases, server to service communication goes through virtualized IP which is handled by load balancer.
Unsurprising, not many people understand the complication of LB in the middle and how to turn WCF parameters to work
around it. Consequently,
MessageSecurityException
happens after service goes online, and it becomes difficult to tune the parameters without making breaking change.
Threading
This is more coding issue than WCF framework problem – service contracts are often defined as sync API, and this is
what people feel more comfortable to use. When the server receives short burst of requests and the processing gets
stuck, the number of I/O completion port threads increases sharply, often times the server can no longer receive more
requests. To be fair, this is configuration problem of service
throttling, but
uninformed engineers mistakenly treat it as WCF issue.
Support on .NET core
There is no supported way to host WCF service in a .NET core program, and the replacement is ASP.NET core
gRPC. Forward-looking projects move
away from WCF rightfully.
The general impression is WCF is slow and the scalability is underwhelming. In some case it is true. For instance when
using WS federation HTTP, SOAP XML serialization performance isn’t satisfying, payload on the wire is relatively large
comparing with JSON or protobuf, now adding over 10 kB of authentication header (correct, it is that large) to every
request you won’t expect a great performance out of that. On the other hand, NetTcp can be very fast when authentication
isn’t a factor – it is slower than gRPC but much faster than what control plane services demand. Much of the XML
serialization can be tuned to be fast. Unfortunately, few people know how to do it and leave most parameters as factory
default.
Easy mistakes in data contract
With too much power, it is easy to get hurt. I have seen people use various options or flags in unintended way and are
surprised later. The latest one is
IsReference on
data contract and
IsRequired
on data members misconfiguration. Human error it is, people wish they didn’t have to deal with this.
RPC inside transaction
Making WCF calls gives inaccurate impression that the statement is no different from calling a regular method in another
object (maybe for novices), so it is casually used everywhere including inside of IMOS transactions. It works most of
time until connection issue arises, then we see mystery performance issue. Over time, people are experienced to steer
away from anti-patterns like this.
As we can see, some of the problems are caused by WCF but many are incorrect use pattern. However, the complexity is
undisputable, the perception is imprinted in people’s mind. We have to move forward.
By the way, I must point out that WCF use does not correlate with low availability or poor performance directly. For
instance, the SLA of a foundational control plane service is hovering around four to five 9’s most of time but it is
still using WCF as both server and client (i.e. communicating with other WCF services).
REST using ASP.NET
It is no doubt that ASP.NET is superior in many aspects. The performance, customizability, and supportibility is
unparalleled. Many services moved to this framework before the current recommendation becomes mainstream. However, it
does have more boilerplate than WCF, not as convenient in some aspects.
Message exchange
Some projects use custom solution for highly specialized scenarios. For instance, exchange
bond messages over TCP or HTTP connection, or even customize the
serialization. This is hardly “RPC” and painful to maintain. Over time this approach is being deprecated.
Protobuf over gRPC
As many .NET developers can see, gRPC has more or less become the “north star” as far as RPC concerned. Once green light
is given, the prototyping and migration has started. Initially it was Google gRPC, later ASP.NET
core gRPC becomes more popular because of integration with ASP.NET,
customizability, and security to some extent. The journey isn’t entirely smooth, for instance people coming from WCF
background has encountered several issues such as:
- Inheritance support in protobuf.
- Reference object serialization, cycling in large object graph.
- Managed type support, such as Guid, etc.
- Use certificate object from certificate store instead of PEM files.
- Tune of parameters to increase max larger header size to handle oversized authentication header (solved already).
Usually people find a solution after some hard work, and sometimes a workaround or adopting new design paradigm. In a
few cases, the team back off to ASP.NET instead. Overall trend of using gRPC is going up across the board. Personally I
think this will be beneficial for building more resilient and highly available services with better performance.